
How segmentation issues are a data quality problem
In our ongoing blog series, designed to complement The Trailblazer’s guide to marketing, sales, and RevOps excellence, we previously explored how improving your account data quality can resolve many Ideal Customer Profile (ICP) issues and how addressing duplicate accounts and records can significantly enhance your data integrity. In this installment, we focus on the critical role of data quality in effective segmentation. By ensuring your data is clean, consistent, and comprehensive, you can optimize your segmentation strategy, leading to more targeted and successful marketing and sales efforts. This blog and accompanying ebook provide a comprehensive roadmap to enhancing your RevOps data quality strategy.
Improving data segmentation with data quality
So, maybe your segments aren’t the problem; it’s your data quality.
Segmentation seems like an easy thing. Take a category, and sort it into groups. Ta-da! You’re done. But if the information that needs to be sorted into groups is poorly formatted, contains typos, or is incomplete, your segmentation isn’t as comprehensive as you need it to be.
Inconsistent executive titles affecting data segmentation
For example, if you’re creating a table with executive titles because you want to know how many and which C-level titles you have in your database, your data might look like this:
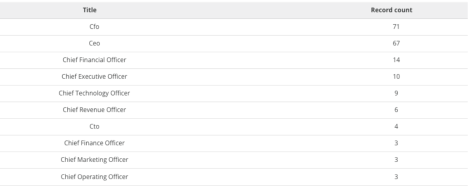
You can see you’ve already got a problem. You have CFO at the top, but you also have Chief Financial Officer as the third line down and Chief Finance Officer closer to the bottom. You have CEO, but also Chief Executive Officer. You Chief Technology Officer, but also CTO. Something is wrong, and the first time you present this table to anyone, they’re going to call that out.
Standardizing titles for accurate segmentation
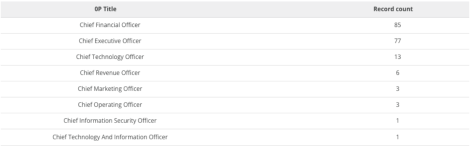
But you do have options. If you can clean that data before you segment it, you can put the right things in the right buckets:
Geographical segmentation challenges
Another example is geographical. If you’re trying to put on an event in the greater New York City area, you can define an area and try to find all the city/state combinations in that area, including the ones in New Jersey and Connecticut. Or you can clean up your data first. The U.S. Census defines urban areas, but it does so based on zip code. If you only have city and state, you’ll miss some this way also.
|
City |
State |
Zip Code |
|
Mt Kisco |
NY |
|
|
06807 |
||
|
New York |
NY |
10001 |
|
Hoboken |
NJ |
With the data above, only two of your four records would end up being processed for the metro area data based on zip code.
Enhancing geographical data for better segmentation
If you use the city/state information to populate a “close enough” zip code for the purposes of finding the urban area, you can mine your own existing data and get even more out of it.
|
City |
State |
Zip Code |
|
Mt Kisco |
NY |
10549 |
|
06807 |
||
|
New York |
NY |
10001 |
|
Hoboken |
NJ |
07030 |
Now you have all four records that can be identified. And if you have other references at your disposal, you can even figure out that 06807 is Cos Cob, CT.
Impact of data quality on segmentation at scale
Obviously, the usual database size for a company is not 4 records, so you can imagine how this plays out at scale. Maybe instead of inviting 5,607 people to your event, you can invite 8,374. If you can invite 1½ times as many people, you could get 50% more responses, 50% more attendees, 50% more conversations, and 50% more opportunities. You get the picture.
Solving segmentation issues through data quality improvement
Multiple segmentation issues can be solved, just with the improvement in data quality.
Want to learn more about improving your segmentation issues? Download The modern b2b segmentation handbook to make your data actionable with a well-segmented database, or watch the Openprise Master Class on Segmentation: you’ve already got data, now let’s make it useful.
If you’re ready to take the next step, schedule a demo today!
Recommended Resources